A desktop environment's sole role is to connect users to their applications. This includes everything from launching apps to actually displaying apps but also managing them and making sure they run fairly. Everyone is familiar the concept of a "Task manager" (like ksysguard), but over time they haven't kept up with the way applications are being developed or the latest developments from Linux.
The problem
Managing running processes
There used to be a time where one PID == one "application". The kwrite process represents Kwrite, the firefox process represents Firefox, easy. but this has changed. To pick an extreme example:
Discord in a flatpak is 13 processes!
It basically renders our task manager's process view unusable. All the names are random gibberish, trying to kill the application or setting nice levels becomes a guessing game. Parent trees can help, but they only get you so far.
It's unusable for me, it's probably unusable for any user and gets in the way of feeling in control of your computer.
We need some metadata.
Fair resource distribution
As mentioned above discord in a flatpak is 13 processes. Krita is one process.
- One will be straining the CPU because it is a highly sophisticated application doing highly complicated graphic operations
- One will be straining the CPU because it's written in electron
To a kernel scheduler all it would see are 14 opaque processes. It has no knowledge that they are grouped as two different things. It won't be able to come up with something that's fair.
We need some metadata.
(caveat: Obviously most proceses are idling, and I've ignored threads for the purposes of making a point, don't write about it)
It's hard to map things
Currently the only metadata of the "application" is on a window. To show a user friendly name and icon in ksysguard (or any other system monitor) we have to fetch a list of all processes, fetch a list of all windows and perform a mashup. Coming up with arbitrary heuristics for handling parent PIDs which is unstable and messy.
To give some different real world examples:
- In plasma's task manager we show an audio indicator next to the relevant window, we do this by matching PIDs of what's playing audio to the PID of a window. Easy for the simple case... however as soon as we go multi-process we have to track the parent PID, and each "fix" just alternates between one bug and another.
- With PID namespaces apps can't correctly report client PIDs anymore.
- We lose information on what "app" we've spawned. We have bug reports where people have two different taskmanager entries for "Firefox" and "Firefox (nightly)" however once the process is spawned that information is lost - the application reports itself as one consistent name and our taskbar gets confused.
We need some metadata.
Solution!
This is a solved problem!
A modern sysadmin doesn't deal in processes, but cgroups. The cgroup manager (which will be typically systemd) spawns each service as one cgroup. It uses cgroups to know what's running, the kernel can see what things belong together.
On the desktop flatpaks will spawn themselves in cgroups so that they can use the relevant namespace features.
You're probably already using cgroups. As part of a cross-desktop effort we want to bring cgroups to the entire desktop.
Example
Before and after of our system monitor
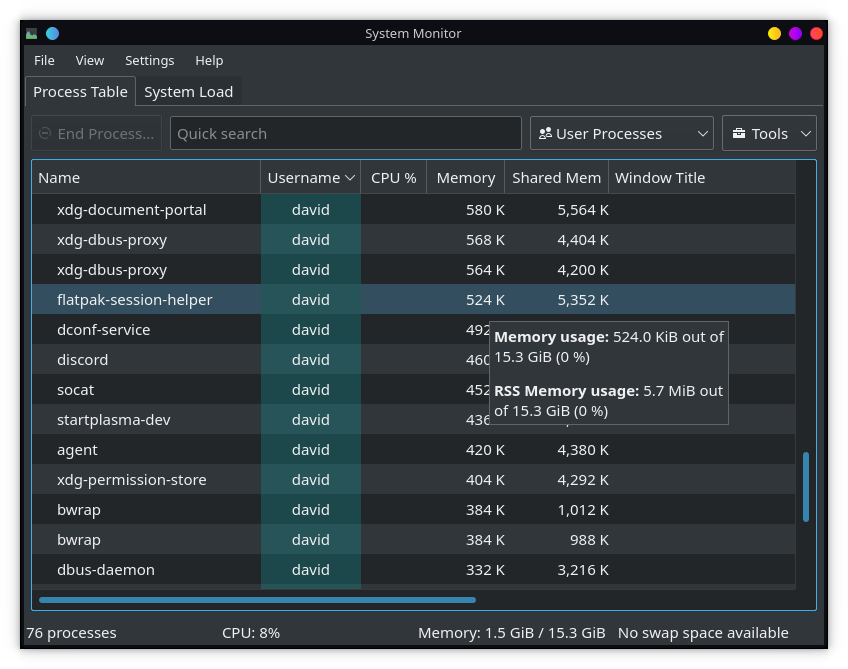
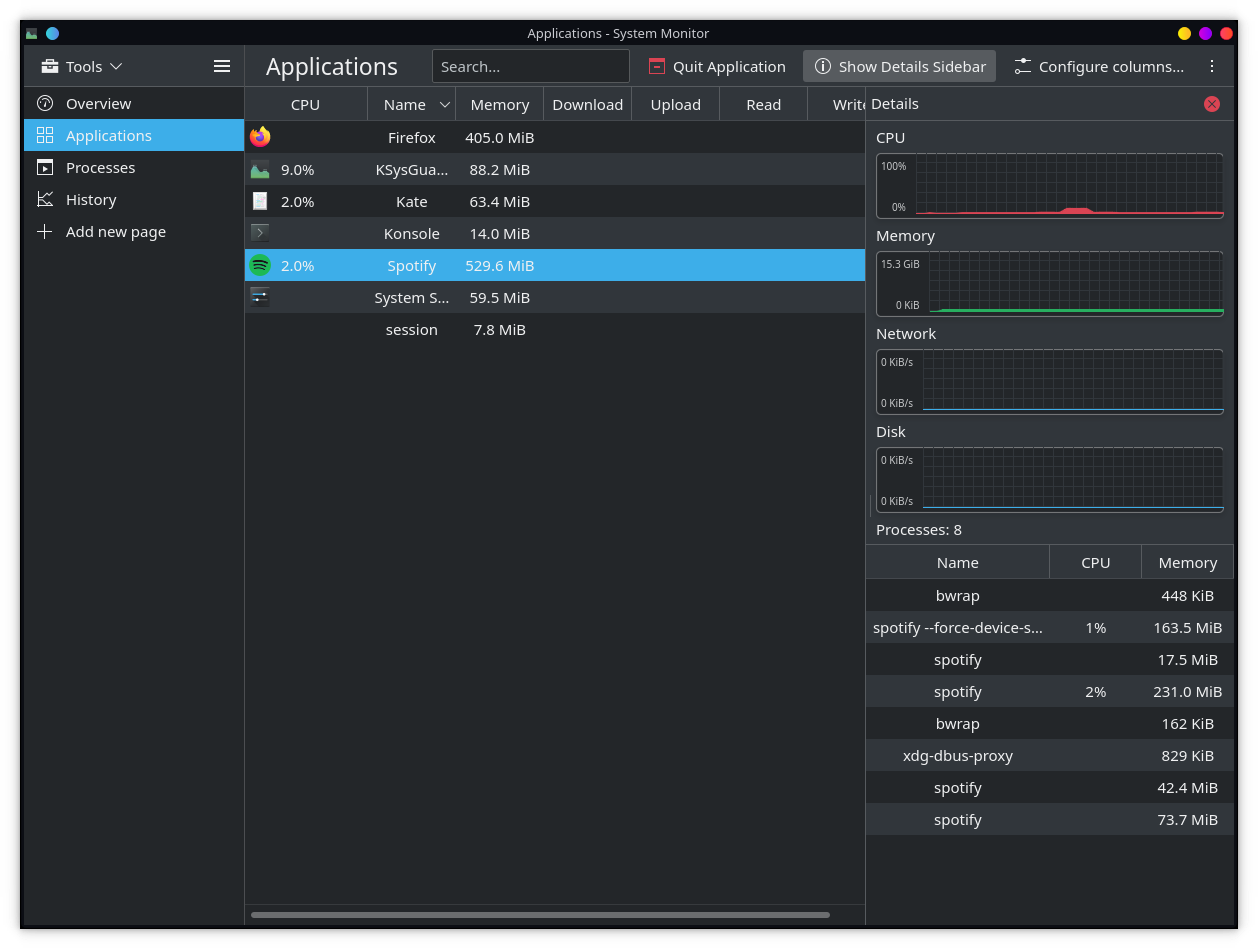
Ultimately the same data but way easier to read..
Slices
Another key part of cgroup usage is the concept of slices. Cgroups are based on a heirachical structure, with slices as logical places to split resource usage. We don't adjust resources globally, we adjust resources within our slice, which then provides information to the scheduler.
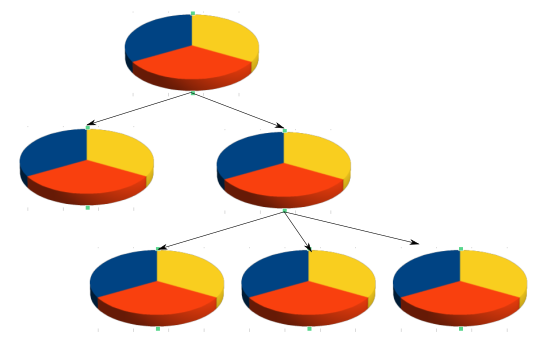
Conceptually you can imagine that we just adjust resources within our level of a tree. Then the kernel magically takes care of the rest.
More information can be found on slices in this excellent series World domination with cgroups.
Default slices
This means we can set up some predefined slices. Within the relevant user slice this will consist shared of
- applications
- the system (kwin/mutter, plasmashell)
- background services (baloo, tracker)
Each of these slices can be given some default prioritisations and OOM settings out of the box.
Dynamic resource shifting
Now that we are using slices, and only adjusting our relative weight within the slice, we can shift resource priority to the application owning the focused window.
This only has any effect if your system is running at full steam from mulitple sources at once, but it can provide a slicker response at no drawback.
Why slice, doesn't nice suffice?
Nice is a single value, global across the entire system. Because of this user processes can only be lowered, but never raised to avoid messing with the system. With slices we're only adjusting relative weight compared to services within our slice. So it's safe to give the user full control within their slice. Any adjustments to an application, won't impact system services or other users.
It also doesn't conflict with nice values set by the application explicitly. If we set kdevelop to have greater CPU weight, clang won't suddenly take over the whole computer when compiling.
Fixing things is just the tip of the iceberg
CGroup extra features
CGroup's come with a lot of new features that aren't available on a per-process level.
We can:
- Set limits so that a CPU can't use more than N%
- We can gracefully close processes on logout
- We can disable networking
- We can set memory limits
- We can prevent forkbombs
- We can provide hints to the OOM killer not just with a weight but with expected ranges that should be considered normal
- We can freeze groups of processes (which will be useful for Plasma mobile)
...
All of this is easy to add for a user / system administrator. Using drop in's one can just add a .service file [example file link] to ~/.config/systemd/user.control/app-firefox@.service and manipulate any of these.
[caveat, some of those features works for applications created as new transient services, not the lite version using scopes that's currently merged in KDE/Gnome - maybe worth mentioning]
Steps taken so far
Plasma 5.19 and recent Gnome now spawn applications into respective cgroups, but we're not yet surfacing the results that we can get from this.
For the KDE devs providing the metadata is easy.
If spawning a new application from an existing application be sure to use either ApplicationLauncherJob or CommandLauncherJob and set the respective service. Everything else is then handled automagically. You should be using these classes anyway for spawning new services.
For users, you can spawn an application with either kstart5 --application foo.desktop"
That change to the launching is relatively tiny, but getting to this point in Plasma wasn't easy - there were a lot of edge cases that messed up the grouping correctly.
- kinit, our zygote process really meddled with keeping things grouped correctly
- drkonqi, our crash handler and application restarter
- dbus activation has no knowledge of the associated .desktop file if an application is DBus activated (such as spectacle our screenshot tool)
- and many many more papercuts throughout of different launches
Also to fully capitalise on slices we need to move all our background processes into managed services and slices. This is worthy of another (equally lengthy) blog post.
How you can help?
It's been a battle to find these edge cases.
Whilst running your system, please run systemd-cgls and point out any applications (not background services yet) that are not in their appropriate cgroup.
What if I don't have an appropriate cgroup controller?
(e.g BSD users)
As we're just adding metadata, everything used now will continue to work exactly as it does now. All existing tools work exactly the same. Within our task manager we still will keep a process view (it's still useful regardless) and we won't put in any code that relies on the cgroup metadata present. We'll keep the existing heuristics for matching windows with external events, cgroup metadata would just be a strongly influence factor in that. Things won't get worse, but we won't be able to capitalise on the new features discussed here,
On my system I have a few applications running under the session scope (for example, now the cgroup is called ‘session-3.scope’). For example:
– slack
– variety
– Duplicati
– mate-optimus-applet
– syncthing-gtk
– Keybase
– Eclipse (though there is a apps-eclipse-.scope, but it only contains the shell that runs the `Exec` command for the launcher, everything else in that hierarchy is under the session scope)
How do I make them go into an application scope? I tried to figure out what causes Firefox to be in its own scope but not Keybase, but there is nothing the desktop entry that seems relevant.
Two might be because of the hyphen in the name. I think there was release of frameworks that didn’t escape that correctly.
Fortunately that’s why we have this slow roll out where we are adding the metadata before relying on using it.
As for the others, the key part is about what’s launching them. Autostart isn’t covered yet – though will be. Session restore might only be in master not 5.19.
That eclipse case sounds interesting, I’ll install it and see if I can reproduce.
I have pretty-much every app except for some system services (gvfs, dbus) and docker containers directly under “session-6.scope”
Running KDE Neon User Edition, Plasma 5.19.2
Restarting Slack caused it to fall under its own scope, so I’m assuming Slack, Variety, Duplicati, mate-optimus-applet and synchthing-gtk are due to autostart/session restore.
Keybase is usually being run by a user service (keybase.gui.service) and when started like that it falls under its service cgroup. Its possible that the artifact from before was also a session restore issue (Keybase seems to have weird interaction with session restore and suspend/resume. Brings into sharper focus the question of why have a GUI run as a service).
Eclipse for me is a local installation of the download from eclipse.org, where the desktop launcher is manually created and the Exec line does some shell work to manipulate the exec command to load arbitrary files. The launcher looks like this:
[Desktop Entry]
Categories=Development;
Encoding=UTF-8
Exec=/home/odeda/.local/eclipse-2020-03/eclipse/eclipse -dev $(ls ~/.m2/repository/javax/xml/bind/jaxb-api/*/*[0-9].jar | tail -n1)
Icon=eclipse
Name=Eclipse IDE
NoDisplay=false
StartupNotify=true
Terminal=false
Type=Application
I don’t know if the weird stuff on the exec line has something to do with it, but I always launch Eclipse manually (session restore doesn’t like it for some reason).
After restarting Eclipse, now the shell is still under the apps-eclipse-*.scope, and the two other processes (eclipse executable and Java vm) are under the apps-plasmashell-*.scope …
I must wrote giving higher priority to application owning focused window is Windows feature. Windows had this implemented very long.
Checked my applications, and the ones that were placed into a session-2 group were Microsoft teams (electron) and hdfview (java). The latter is a program that isn’t widely used, but there’s probably a lot of people that use ms teams.
Heres my cgls ungrouped scope: https://gist.github.com/Korvox/644a4dd9bc497d8ede93935e9a4afe6a
Most of it is the aformentioned autostarting programs, but strangely Krita and Chromium aren’t getting grouped despite not being autostarted or restored. Also of note session restore is properly grouping restored kdevelop, firefox, clementine, and ktorrent.
What an awesome blog, really nice write-up, thanks!
The only thing I see fishy on my system is teams in the session-slice:
session-2.scope
│ ├─1735 /usr/share/teams/teams
│ ├─1737 /usr/share/teams/teams –type=zygote –no-sandbox
│ ├─1795 /usr/share/teams/teams –type=renderer –autoplay-policy=no-user-gesture-required –enable-features=Sha>
Teams was started using krunner/app icon/start menue, so I guess the .desktop-file is evaluated.
I guess, that the desktop file is provided by my distribution (arch) and not by KDE. Thus, should I report to the distribution?
So, a few months ago, tired of all the ram being eaten by firefox, I had been experimenting with cgroups a bit. So I created a slice within ~/.config/systemd/user with memory limit set and ran my browser from a konsole with a command like systemd-run –user –slice=*slice* firefox. Not a particularly useful experience – OOM killed not just some child, by the whole thing once the limit was reached. It left me disappointed. But now i see that maybe I was doing it the wrong way. Keep up with good work!
Btw my cgls:
https://pastebin.com/V6MPdftF
Why system load in the same window with the other process’s data? Is there any reason for that? I feel like it’s stuffing too many things in a limited space.
I like that we have different tabs with different views, so having processes on one tab, system load on another, then some custom tabs with thermal or IO Scheduler, etc. I didn’t see on the example screen.
I launched Firefox from Thunderbird by clicking on a link and that put it into the session slice. Is that the correct behavior? Restarting it put it under the apps slice.
‘you can spawn an application with either kstart5 –application foo.desktop”’
…or what? This sentence is incomplete. `kstart5` doesn’t work for me in KDE Plasma 5.18.5/KDE Frameworks 5.70.0 with that command line so I assume it’s new functionality, nor does it work with its documented`-desktopfile foo.desktop` option. Instead I’ve been using `gtk-launch foo.desktop` instead
All this should lead to a more responsive desktop and better OOM behavior, exciting. Maybe the UI for limiting slices’ resource usage could be pie slices of pie slices all the way down ?
“One will be straining the CPU because it is a highly sophisticated application doing highly complicated graphic operations
One will be straining the CPU because it’s written in electron”
classy bougie ratchet
awesome work.
A translation in Greek language: https://linux-user.gr/t/mia-sygchronh-diacheirish-diergasiwn-gia-thn-epifaneia-ergasias/2343
efcharistó !
Can this help with monitoring CPU and network usage per application?
Absolutely!